
I'm a research software engineer with a background in chemistry. My main interest is in architecting, implementing, and maintaining stable software systems that benefit researchers in the long-term. I currently work at TU Delft, where my current focus is on improving the performance and maintainability of open-source biomechanical simulation software (e.g. OpenSim).
🌟 Portfolio
This portfolio represents a small subset of those projects because some of my work has been internal or commercial. Download a copy of my CV here.
-
-
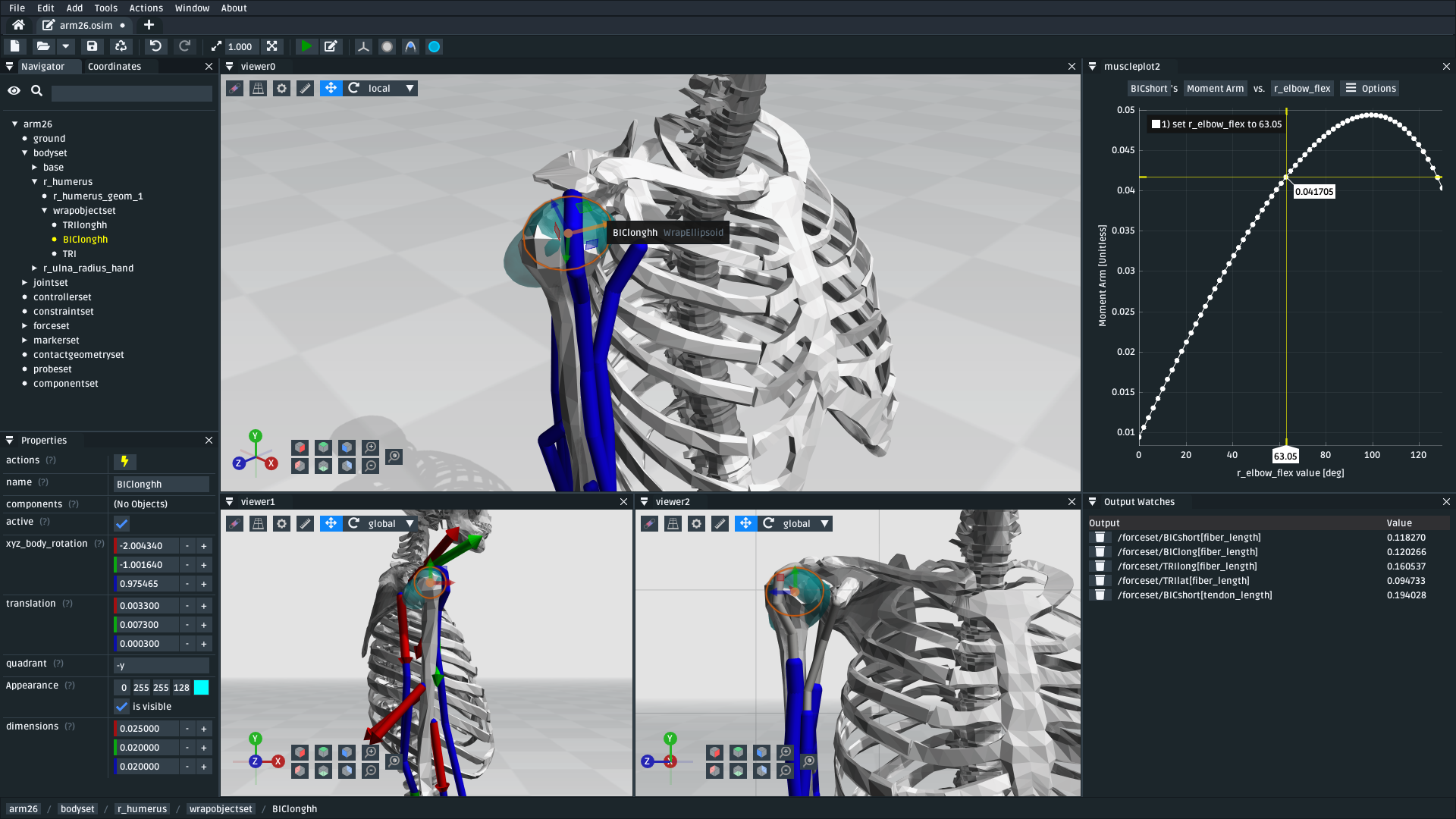
OpenSim Creator is an open-source self-contained GUI for creating and editing OpenSim models. It is developed with C++, OpenGL, and OpenSim.
- Enables users to create OpenSim models without having to write code or XML
- Standalone installers on Windows, Mac, and Linux
- High-performance C++ and OpenGL. Runs smooth (>60FPS) on a low-end laptop
-
-
Jobson is an open-source platform for transforming command-line applications into a job service. It is developed with Java, Typescript, and React.
- Enables implementors to create web services around their applications by writing a simple YAML job specification
- Provides an easy-to-use UI for end-users
-

-
I also work on various small side-projects, such as:
- libdeflater, a Rust (❤️) library for zlib compression
- eink-harmonograph, a C++ Arduino project for drawing harmonographs on an eink screen
- xdc, python bindings to XSens DOT's Bluetooth Low-Energy (BLE) interface
- ta-rust, a Rust application for hosting command-line games through a browser
- plateyplatey, a Typescript angular UI for editing lab plates
- fo2dat, a Rust application for extracting Fallout 2 DAT archives
- presentation-combiner, a C#/F# WPF UI for combining powerpoint slides
-

-
My gallery page contains various pieces of design work I have produced. Examples of things I have worked on:
- Cover design for Agnewandte Chemie
- Cover design for Nature Chemistry
- Cover design for Nature Materials
- Cover design for Nature Chemistry
- Cover design for Advanced Materials
- Conference booth background for 2017 RSC "Summer of Science" conference
- Cover design for my PhD thesis
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
👔 Experience
Open Source Developer
I work as an open-source software developer at TU Delft. I work in the BioMechanical Engineering department on OpenSim-related projects. My primary project is OpenSim Creator, which is a C++ GUI for creating OpenSim models interactively. Primary responsibilities:
- Designing, developing, and shipping 3D tooling UIs (OpenSim Creator) with C++ and OpenGL
- Performance-engineering legacy C++ codebases
- Organizing and administrating shared compute resources
Software Developer
I worked as a software developer at PetaGene, which is a small (<10 employees) startup company that produces genomic compression software. Primary responsibilities:
- Developed low-level compression systems in C and C++
- Shipped those systems to large enterprise customers with multi-petabyte datasets
- Adopted PetaGene's C/C++ codebase to work in a browser (wasm)
- Developed a web UI for PetaSuite Protect in Typescript + React
- Developed devops. Things like Jenkins build pipelines, development environments, end-to-end system tests, etc.
- Helped manage external developers
Software Developer
I worked in the Institute of Astronomy on the European Space Agency's Gaia project (BBC). My team mostly focused on writing highly-scalable data processing pipelines that needed to handle >1 PB of data per batch.
- Developed Jobson, a Java+Typescript platform that enabled us to transform our data processing applications into web platforms for research use
- Developed Java+Scala codebases that utilized MapReduce and Spark to process large (>1 PB) datasets
- Developed SQL-like DSLs using ANTLR to enable scalably extracting data from the cluster "as if" it were a relational database.
- Developed large-scale data pipelines with Luigi
Automation, Data, and Standardisation Scientist
Used data science and robotics to accelerate practical chemical research. My main focus area was in creating Oracle SQL queries, Pipeline Pilot pipelines, and Tableau dashboards on top of Unilever's existing data systems. I also worked on integrating those systems with lab equipment to increase data collection volume.
Web Designer & Developer
Developed customer-facing webapps and dashboards that were deployed to NHS hospitals nationwide. Full-stack development, but with an emphasis on frontend development. Technologies: Javascript, Ruby, IBM Notes, PostgreSQL, angularjs, highcharts.
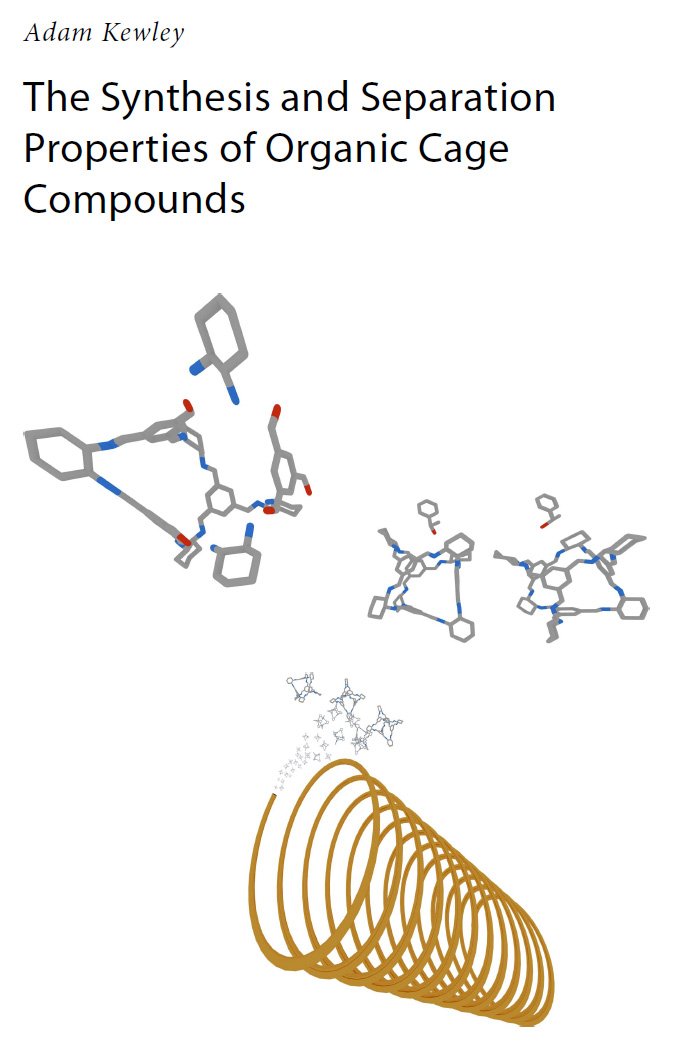
PhD, High-Throughput Organic/Analytical Chemistry
Synthetic and analytical research into porous organic cage compounds. Used robotic platforms (Chemspeed/Eppendorf) to automate the synthesis and analysis of porous organic materials. Primary focus was on conducting analytical experiments to validate computational methods. Supervisor: Andrew Cooper FRS.
Other Experience
- OEE Software Development, Henkan Ltd., Dec 2010 - Feb 2011
- Nuffield Research Placement, University of Nottingham, Jun 2009 - Sep 2009
- Warehouse Operative, NHS, Jul 2006 - Aug 2006
- Nuffield Placement: Civil Engineering, Mouchel Parkman, Jun 2005 - Aug 2005
📖 Education
PhD in Chemistry
University of Liverpool, 2011-2015, Supervisor: Prof. Andrew Cooper FRS. [thesis]
MSc. (hons.) in Nanoscience
University of Nottingham, 2010-2011, Grade: Merit. [dissertation]
BSc. (hons.) in Chemistry
University of Nottingham, 2007-2010, Grade: First.
📰 Publications
Gaia Data Release 2
Astronomy & Astrophysics, 2018, 10.1051/0004-6361/201833051, PDF
Gaia Data Release 2: Processing of the photometric data
Astronomy & Astrophysics, 2018, 10.1051/0004-6361/201832712, PDF
Porous Organic Cages for Gas Chromatography Separations
Chemistry of Materials, 2015, 10.1021/acs.chemmater.5b01112, PDF
Other Gaia Publications
I am an author on these papers because of how the European Space Agency works, rather than because I made any contribution. I only contributed to the above papers (and, even in those cases, minorly because Gaia is a huge project).
- Gaia Data Release 2: Photometric content and validation, link
- Gaia Data Release 2: Kinematics of globular clusters and dwarf galaxies around the Milky Way, link
- Gaia Data Release 2: Observational Hertzsprung-Russell diagrams, link
- Gaia Data Release 2: Mapping the Milky Way disc kinematics, link
- Gaia Data Release 2: Observations of solar system objects, link
- Gaia Data Release 2: The celestial reference frame (Gaia-CRF2), link